El Perfil de la Ciutat

El "negoci" de l'administració pública
Les paraules importen. El que es diu importa, qui ho diu importa, com es diu importa... Sota aquesta premisa, l'administració pública ha de ser molt curosa amb les paraules que utilitza, i deixar de manllevar paraules i conceptes provinents del món empresarial
Llegir l'article
Què és el talent?
Article en el que s'intenta explicar que és el talent basant-se en el concepte d'efectivitat, el qual al mateix temps es basa en dos conceptes: eficiència i eficàcia
Llegir l'article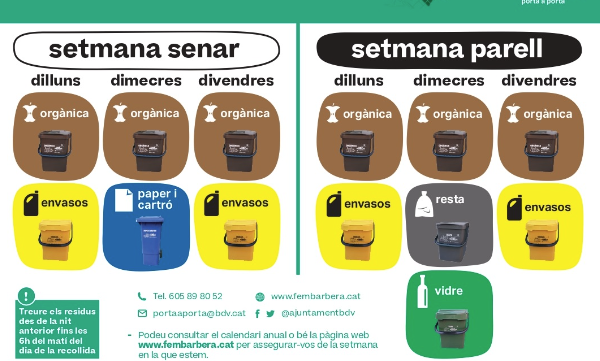
Els petits canvis als residus són poderosos i necessaris
Article en el que es desgranen els diferents sistemes de recollida de residus que s'estan implantan als municipis del Perfil de la Ciutat
Llegir l'article
Activitats econòmiques amb distribució extrema dels llocs de treball per sexe
En aquest article, s'aplica als municipis del Perfil de Ciutat, el primer indicador “Labour-force participation rate (%)” de la primera dimensió, “Economic Participation and Opportunity” de "l'Informe global de la bretxa de gènere" realitzat pel Fòrum Econòmic Mundial
Llegir l'articleDestaquem

Com afectarà el control del preu de lloguer als propietaris?
URBAN3R Plataforma de Dades Obertes per impulsar la regeneració urbana a Espanya
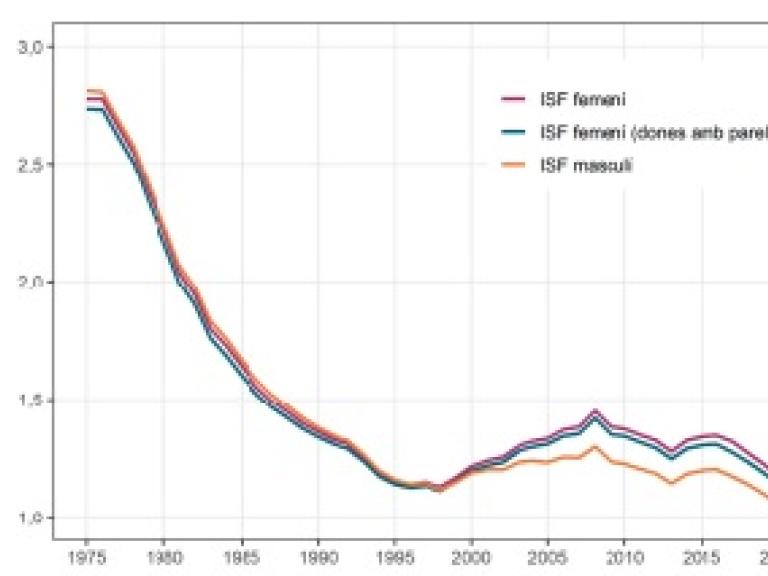
I ells què? La fecunditat masculina a Espanya
El mapa de la ciutat dels 15 minuts a Espanya

Informe econòmic local de la Província de Barcelona 2022
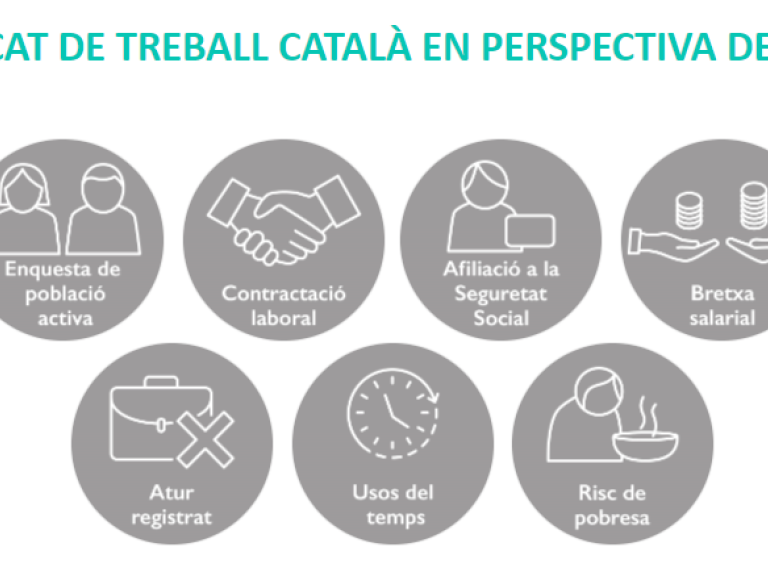
El mercat de treball català en perspectiva de gènere

Com serà la població l’any 2031 a les comarques i els municipis catalans?
Cens 2021
Accedeix a l'anuari d'enguany i consulta el capítol que més t'interessi
Articles
O, si ho prefereixes, consulta les dades de la teva ciutat
Rep les darreres notícies al teu e-mail